|
Автоматизация обработки неструктурированной текстовой информации Статья опубликована: Автоматизация обработки неструктурированной текстовой информации и перспективы гуманитарных наук в XXI веке. // Человек-текст-эпоха. Томск: Изд-во ТГУ, 2011. Вып. 4. С. 15-37. Статья посвящена проблеме автоматизации тематической индексации текстов и её роли в развитии гуманитарных наук вообще и исторической науки в частности. В статье представлена оригинальная авторская модель разработки тематического поисковика на основе использования байесовской концепции вероятности в тематической индексации текстов. Одна из глобальная проблем XXI века – это так называемый «информационный взрыв» или рост диспропорции между объёмом информации, произведённой человечеством, и объёмом информации, которую люди способны потребить и усвоить. Осмысление и решение данной проблемы чрезвычайно актуально для исторической науки, равно как и для всей гуманитаристики. Достаточно указать на то, что в наши дни почти каждая вузовская кафедра имеет возможность регулярно издавать один или несколько объёмных сборников статей или коллективных монографий каждый год. В итоге в узких предметно-тематических областях лавинообразно накапливаются никем неосвоенные «завалы» информации. С одной стороны, эта лавина информации вызвана не столько расцветом науки, сколько конъюнктурными потребностями: количество и статус публикаций важнее их содержательного качества, оригинальности и практической актуальности. С другой стороны, необходимы специальные стимулы и поводы к прочтению или хотя бы к ознакомлению с огромным количеством отдельных текстов для оценки их содержательных свойств. Такие поводы и стимулы может создать только автоматизированная организация баз знаний, в которых всё содержание текстов будет автоматически структурироваться и ранжироваться по множеству всех возможных тематических рубрик. [С. 15] Информационный взрыв порождает избыток неиспользуемой информации и хаос неструктурированной информации. Поэтому один из главных путей выхода из сложившейся ситуации – превращение неструктурированной информации в структурированную. На этом пути будут изменяться способы организации и цели исследовательской деятельности во всех гуманитарных науках. Исторических дисциплин это должно коснуться в наибольшей степени. Во-первых, потому что весь массив накапливаемой и сохраняемой в электронном виде текстовой информации – это потенциальный архив исторических источников, во-вторых, потому что историческая наука способна аккумулировать в себе концепции и методы всех остальных гуманитарных дисциплин. Превращение неструктурированной информации в структурированную – главная цель контент-анализа текстов, являющегося особым способом сокращения пути читателя от языковых средств выражения к идеям. Субъектами структурирования информации могут быть как люди (ручной контент-анализ), так и компьютерные программы (автоматизированный контент-анализ). Ручной контент-анализ в современных условиях в любом случае связан с использованием компьютера и возможностей частичной автоматизации поиска единиц текста. Автоматизация контент-анализа – это нечто большее. По сути, это замена человеческого интеллекта искусственным. В случае полной автоматизации анализа экспертной компьютерной программой без участия человека производится толкование текстов, сведение их содержания к названиям и обозначениям тематик, фактов или смыслов для отображения их в виде: 1) свойств и атрибутов файлов, 2) иерархического дерева папок, 3) полей базы данных. Исследователю остаётся только указать, какие тексты нужно изучить и нажать на одну или на несколько кнопок. В Таблице 1. приведена авторская система определений понятия «Неструктурированная текстовая информация». При автоматическом анализе содержания текстовых документов посредством контент-анализа происходит перевод всех свойств текста из левого столбца нижеприведённой таблицы в правый столбец. [С. 16]
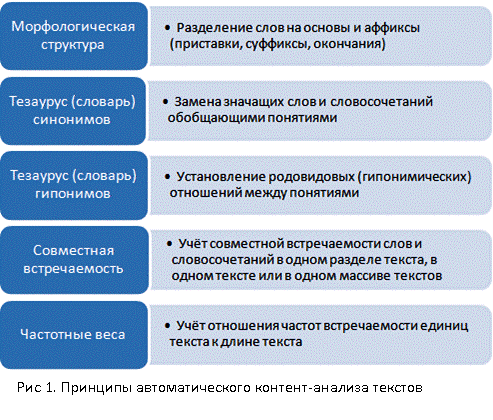
[С. 17] Теоретические и методические основы автоматического анализа содержания текстовых документов были разработаны ещё на начальном периоде истории компьютеров в 1960-х годах, и с тех пор концептуальных изменений в данной области не наблюдалось. Одним из ведущих разработчиков этого направления в частности был американский учёный Г. Сэлтон (Gerard Salton). В своей книге «Автоматическая обработка, хранение и поиск информации» (1968г.) он перечисляет несколько принципов1 , которые в упрощённом виде представлены на Рис. 1.:
Современным компьютерным системам доступно использование разного рода
многомерных методов глубинного извлечения информации (data
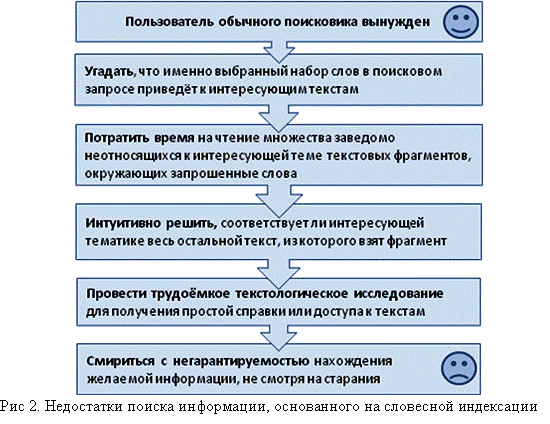
mining) таких как, например, кластерный анализ или нейронные сети. Все поисковые системы используют контент-анализ для индексирования файлов с текстовой информацией. Индекс представляет собой таблицу, в которой каждому слову сопоставляется место хранения файла, в котором это слово встречается, и место в этом файле, где стоит это слово. Индексные файлы необходимы для того, чтобы при поисковом запросе пользователя не перебирать каждый раз заново слово за словом всё содержание текстов. Ведь этих текстов могут быть многие миллиарды (например, в глобальной сети). При поисковом запросе или при построении классификаций документов обрабатываются уже не файлы с текстами, а только эта таблица-указатель, что многократно ускоряет поиски. Разные поисковые и экспертные системы отличаются оптимальностью алгоритмов построения таких таблиц-индексов и эффективностью управления ими. В тоже время поиск информации, основанный на словесной индексации связан с множеством недостатков (см. Рис. 2).
[С. 19] От этих недостатков можно было бы избавиться, если бы индексация представляла собой некую тематико-смысловую предопределённую пользователем фильтрацию. Такая фильтрация давала бы возможность упорядоченного выбора из массива текстов, равно как и из набора фрагментов крупных текстов, структурированных по содержательно-смысловым критериям. Попытка реализовать такую задачу на практике неизбежно ведёт к вопросу: как сделать, чтобы результаты поискового запроса не только соответствовали (были релевантными) наличию в текстах заданного набора слов, но и соответствовали тематикам, интересующим человека? С этим вопросом связано понятие «пертинентность» (от англ. pertinent – «относящийся к делу», «подходящий по сути»), используемое в современной семантике и в теориях поисково-информационных методов. Количественно пертинентность измеряется как соотношение объема полезной информации к общему объему полученной информации. В отечественной науке соотношении пертинентности и релевантности одним из первых начал изучать выдающийся библиотековед и социолог А.В. Соколов2 . Из современных русскоязычных авторов, наиболее активно касающихся этой проблематики, стоит назвать также специалиста в области семантического обеспечения интернет-сервисов Д.В. Ландэ3. Если приблизить модель контент-аналитических подсчётов к модели тематического толкования текстов человеком, то организация и результаты информационного поиска станут более пертинентными конкретным информационным потребностям пользователей, а не просто релевантными запросу на встречаемость слов и словосочетаний. В настоящей статье предлагается способ повышения пертинентности информационных запросов эффективного поиска путём использования автоматизированного построения индекса тематического рубрицирования. До сих пор корректное тематическое рубрицирование текста было под силу проводить только человеку-эксперту. В тематическом индексе каждому целостному фрагменту текста сопоставляется
перечень тематических рубрик (контекстов) для каждой из которых указан её
уровень или степень (вес, доля, процент) доминирования по отношению к другим
контекстам в данном фрагменте текста. В традиционных поисковых системах одно и то же слово ищется в разнотематических текстах. В отличие от них, система с тематической индексацией позволила бы искать правильно понятые по смыслу синонимические и гипонимические ряды в документах по одной тематике, без выдачи информационного мусора. Следует отметить, что в последние годы уже начали появляться интернет-сервисы, которые по ключевым словам вычисляют степень присутствия на web-странице некоторых наиболее общераспространённых тематик и жанров. Например, они могут отличать научный текст от остальных жанров. Из русскоязычных Интернет-сервисов, способных на такое, можно указать сервис "Семантическое Зеркало" http://www.ashmanov.com/tech/semantic/demo . Тем не менее, вычислить степень доминирования узких тематик, интересующих пользователя, такие сервисы не способны. Попытка практической разработки тематической авторубрикации текстов неизбежно будет начинаться с концептуальной проблемы понимания отличий человеческого и компьютерного способов интерпретации смыслов текста. В чём суть этих различий? Существующие компьютерные программы анализа текстов учитывают ключевые слова, исходя из предположения, что они тождественны по вероятности обозначения одного и того же смысла, и для всех них эта вероятность равна 100%. Однако в реальности, эта вероятность разная, так как в разных контекстах одно и то же слово может иметь разные смыслы. Именно поэтому ни одна поисково-экспертная программа не может самостоятельно и корректно определить, о какой узкой предметной области идёт речь. Человек, в отличие от компьютера, заранее (a priori) знает какие слова или выражения однозначно указывают на тематический контекст, какие могут не всегда, но часто, какие – очень редко, какие – никогда, а какие могут указывать сразу на несколько рубрик. Затем (a posteriori) он соотносит это априорное знание с интерпретируемым текстом. [С. 21] Отличия человеческого и формального компьютерного способов анализа текстов можно осмыслить посредством теории систем. В рамках теории систем, тематическая рубрика текста (контекстный смысл) – это продукт конкретной текстовой системы, а взаимосвязь лексем-индикаторов тематической рубрики – это продуцент (взаимодействие частей системы). Отдельная лексема-индикатор (смысловой маркер) без связи с другими ещё не означает систему, то есть не порождает смысла. Концепция формального перебора словарей индексов как раз и не учитывает продуцент, то есть взаимодействие частей текстовой системы. Соответственно эта концепция не в состоянии обеспечить правильное распознавание смыслов текста, вложенных в него человеком. Различия подходов к автоматизации обработки неструктурированного текста стоит также попытаться представить в контексте парадигм научного познания. Работа авторубрикаторов и поисковиков с сочетаниями знаков в словесных индексах – это по сути учёт только инвариантных формализмов текстовых конструкций. Такая работа строится на методологии неопозитивизма и структурализма. Однако с помощью обработки текстов по такой методологии компьютер не в состоянии, к примеру, различить идёт ли в тексте речь о судах арбитражных или о судах морских. Для программы обработки данных в этом случае словоформа «судах» будет одним и тем же инвариантным формализмом. Математический анализ формализмов текста при таких вычислениях не выходит за рамки того, что в явной форме содержится в тексте. Поэтому обработка текстовых формализмов нуждается в дополнении деконструкцией вероятностных смыслов текста. В основе методологии такой деконструкции лежат постструктуралистский и постмодернистский проекты научного познания. Авторский взгляд на теоретические аспекты такой взаимодополняемости парадигм представлен в Таблице 2. Самым распространённым стандартом библиотечной тематической рубрикации по
принципу онтологии является универсальный десятичный классификатор (УДК),
представляющий собой примерно 143 тыс. концепций, организованных в таксономию.
По каждой рубрике выбираются ключевые слова, определенные библиографом при
библиографическом описании книги. Проблемы с автоматическим поиском нужного
текста на базе УДК возникнут в тех случаях, когда одни и те же ключевые слова
относятся к множеству разных рубрик, а такие случаи встречаются в
библиографических указателях достаточно часто.
[С. 23] Некоторые специалисты предлагают подсчитывать сумму отношений слов из тезауруса или из эталонных текстов по тематике к количеству слов в каждом предложении, и отношение полученной величины к размеру текста6. Не исключено, что эта процедура может оказаться чрезмерно избыточной, сложной и ещё более объёмной, чем полная словесная индексация. Концепция эталонных текстов в сущности предлагает подогнать все новые и нестандартные тексты под один фиксированный по своей структуре и семантике текст (или фиксированную группу текстов, что по сути то же самое). Нет гарантии, что эталонный текст исчерпает всю семантику интересующей нас предметной области. Следовательно, тематическая индексация должна стать менее объёмной, более быстрой, более эвристичной, чем словесная индексация. Только тогда она будет коммерчески выгодной, а, значит, и имеющей перспективы широкого распространения. Для достижения этих целей, на наш взгляд нужно учитывать расхождения человеческих и компьютерных принципов интерпретации тематики текста и попытаться приблизить компьютерные принципы к человеческим. Как было показано выше, при понимании текста человек восполняет информационную неполноту языковых формализмов априорной информацией о культуре и о языке в целом. Каким образом выразить эту информацию в числовой форме и включить её в формулу? Ответ на этот вопрос предполагает обращение к математической концепции,
учитывающей априорные вероятности. Томас Байес (Thomas Bayes) (1702-1761) – английский священник и выдающийся математик, автор фундаментального исследования в области теории вероятностей "Эссе о решении проблем в теории случайных событий". Эта работа была обнаружена только после его смерти и в 1764 г. опубликована в "Трудах Лондонского Королевского общества". Сам Байес, разработав концепцию априорной вероятности, ещё не смог найти нужного математического аппарата для неё. Через 10 лет после его смерти эту задачу решил П. Лаплас. Он представил теорему и формулу Байеса в её современном виде. В самом общем виде, суть формулы Байеса7 – вычисление отношения условной вероятности, введённой априорно человеком, к полной вероятности всех возможных событий в изучаемой ситуации8. Введение в математическую формулу неких "предпосылочных убеждений", может создать впечатление, что любой человек может прийти к любому выводу на основе одних и тех же данных. Это привело к тому, что теорему Байеса многие учёные XX века посчитали субъективной и ненаучной. Вместо неё всю вторую половину XX века приоритет оставался за статистическими методами требовавшими предоставить так называемую величину P, показывавшую вероятность ошибочности выводов для эмпирического апостериорного распределения статистических параметров, описывающих выборку данных. Ведущие научные журналы отказывались публиковать статьи, где статистические данные не сопровождались величиной p-уровня. В исторической науке использование статистических методов для массовых исторических источников также неизменно опиралось и опирается на вычисление p-уровня. Однако некоторые учёные всё же предупреждали, что величина p показывает
достоверность выводов всего лишь при априорном условии, что имело место
счастливое стечение обстоятельств, Эти тенденции привели к тому, что сегодня популярность байесовской парадигмы постоянно растёт. Она задействуется, например, при так называемой "персонализации" когда системы информационных услуг автоматически учитывают в качестве априорной вероятности текущих интересов пользователя содержание его предыдущих запросов. Исходя именно из байесовского подхода, результаты поиска Google иерархически формируются из списков сайтов, которые выбирали другие люди, подавшие аналогичный запрос. Самая знаменитая технология управления неструктурированной информацией, основанная на байесовском подходе – это английская корпорация Autonomy www.autonomy.com . Её создатель Майкл Линч (Michael Lynch) утверждал, что с помощью формулы Байеса можно интерпретировать текст, независимо от того на каком языке он написан, то есть, по сути, без учёта дискурсивно-смысловых особенностей. Для простых производственных задач автоматизации документооборота и ускорения консалтинга клиентов этот подход оправдан. Однако такой подход не привёл и не сможет привести к созданию ожидаемого всем интернет-сообществом интеллектуального поисковика. Решить задачу по созданию интеллектуального поисковика нового типа могут
модели более глубоко учитывающие вероятностную природу человеческого языка. О
вероятностном восприятии языка одним из первых стал писать выдающийся
отечественный учёный В.В. Налимов в своей ставшей уже культовой книге
«Вероятностная модель языка. О соотношении естественных и искусственных языков»
(1-е изд. 1974г.). В.В. Налимов рассуждал о том, что смысл воспринимаемых слов
расплывчатый, размытый, нечёткий, поэтому любое слово может в определённом
контексте и ситуации обозначать любой смысл и любой предмет, а разные смыслы и
предметы могут с разной вероятностью обозначаться одним и тем же словом. Аналитик, использующий байесовском подход, обладает численным выражением
анализируемого неизвестного параметра ещё до начала сбора исходных
статистических данных11.
В нашем случае, при вычислении уровня доминирования определённой тематики в
тексте, вышеупомянутым неизвестным параметром в формуле Байеса может считаться
вероятность восприятия читателем данной тематики как доминирующей в конкретном
тексте. Получая исходные статистические данные (в нашем случая путём
контент-анализа текстов), мы присоеденяем эти данные к ранее имевшейся
информации о параметре (в нашем случае – к информации, полученной путём
дискурсивного анализа предметной области, которой посвящены тексты).
Дискурсивный анализ позволяет установить тезаурус лексических индикаторов для
каждой интересующей нас тематики, которые могут указывать на её наличие в тексте. Проверка наличия в тексте определённой тематики является для компьютерной программы статистической гипотезой. Как известно её проверка в общем случае вычисляется как отношение произошедших событий, делающих истинность гипотезы более вероятной, ко всем возможным событиям в изучаемой выборке. В предлагаемой модели тематической индексации выборкой будет лексический состав анализируемого текста. «Всеми возможными событиями» при этом будут употребления в индексируемом тексте лексических индикаторов всех тематик из ограниченного списка тематик, которые нас интересуют. Это будет исходное предположение человека (аналитика-эксперта), что количество лексических индикаторов именно такое. В любом тексте может быть представлена какая-то доля от этой лексической полноты. Какие тематики и в каком количестве должны быть в индексе? Чем руководствоваться при ограничении потенциально бесконечного смыслового поля? Будем исходить из того, что тема не должна быть слишком общей и определяться для подавляющего большинства текстов из большого массива (порядка нескольких тысяч текстов) или их фрагментов (более 2/3 от полного объёма отдельного текста). В то же время, она не должна быть слишком узкой и редкой, встречаясь в слишком малом (менее 1%) количестве текстов или их фрагментов. Каждое слово или выражение может потенциально выражать множество смыслов относительно разных контекстов и концептов конкретного текста. Необязательно да и невозможно учитывать все эти смыслы и контексты для решения конкретных поисково-прикладных задач. Поэтому величину представленности или доминирования тематики в тексте правильнее будет подсчитывать только относительно других тематик, заранее заданных пользователем в виде ограниченного списка интересующих его тематик. Это позволит учитывать смысловое взаимовлияние разных тематик в рамках одного текста для корректной тематической индексации. Следует подчеркнуть, что в современных поисковых системах такое взаимовлияние не учитывается. Практическая реализация авторского подхода к тематической индексации
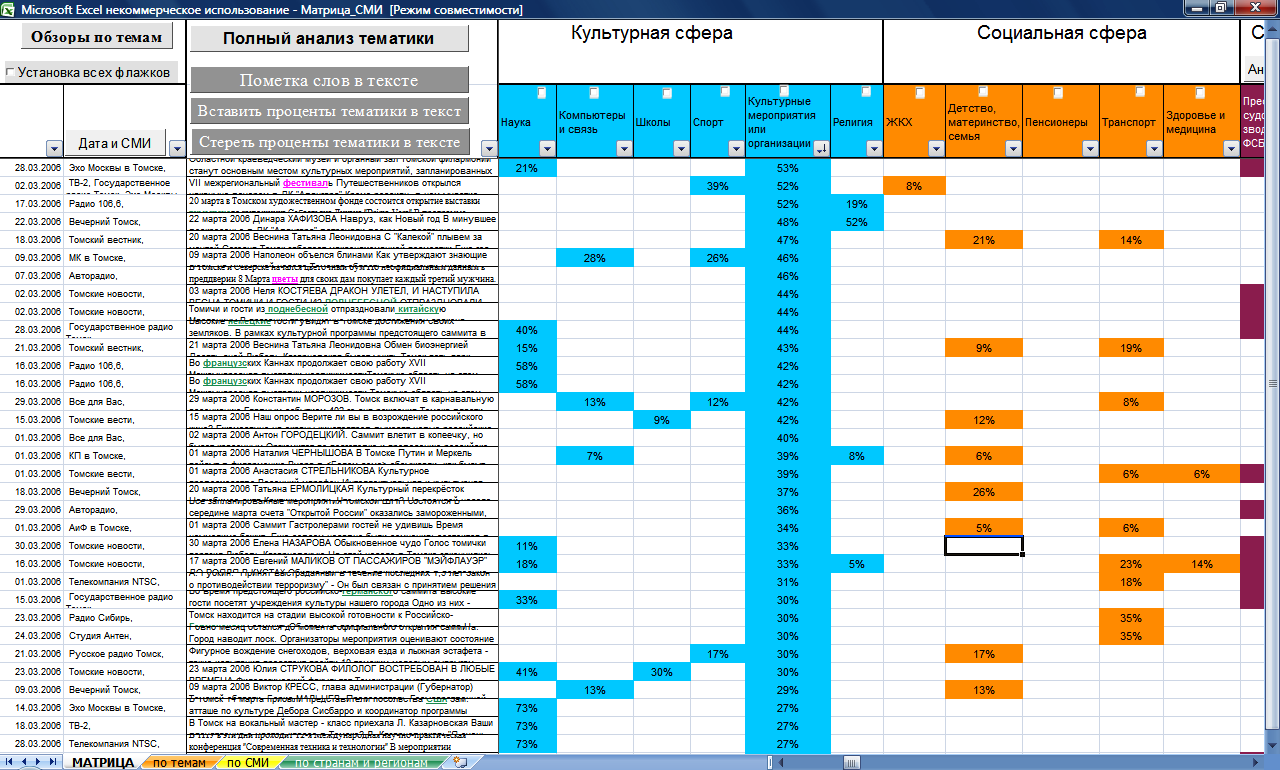
выполнена на базе разработанной автором экспертной компьютерной системы,
предварительно названной «Матрица_СМИ».
Система реализована на базе языка VBA Excel. VBA Excel в данном случае играет для разработчика роль простого и доступного полигона для проверки алгоритмов. При необходимости коммерческой реализации система может быть преобразована в самостоятельный программный продукт на более мощных платформах. Главное ноу-хау в данном случае – это комплекс логико-математических и лингвистических методик, а не интерфейсные (в широком смысле) возможности. Сообщения СМИ и публицистика выбраны в качестве источниковой базы не только из-за их актуальности, но и по методологическим соображениям. Дело в том, что язык СМИ отражает универсальную предметную область. В СМИ может быть написано о чём угодно с употреблением лексики от специально-научной до жаргонно-разговорной. Одновременно язык СМИ – это очень динамичное информационное поле, связанное с отслеживанием всех тенденций в жизни общества и в выразительных средствах языка. Поэтому наиболее продуктивной и показательной разработка и отладка системы автоматической тематической индексации текстов была бы именно для текстов СМИ. В основу предлагаемой компьютерная система была положена разработанная
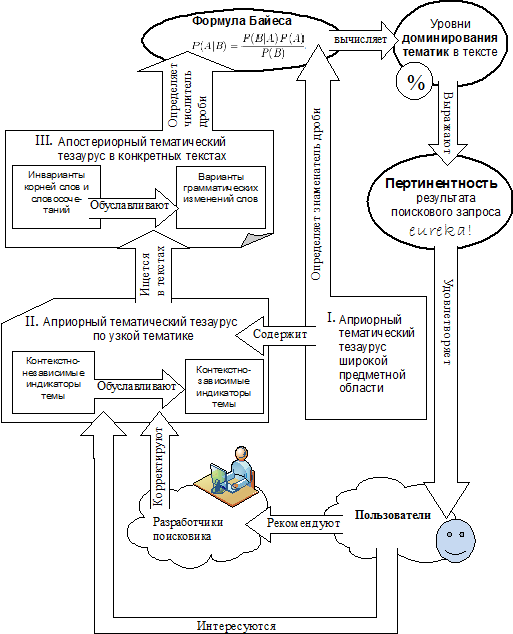
автором модель поисковой системы, ориентированной на пертинентность результатов
запроса. На Рис. 4. эта модель оформлена в виде когнитивной семантической карты
и визуально обобщает взаимосвязь лингвистических, математических и
поисково-сетевых аспектов, на которых может быть основана тематическая
индексация. Далее эти аспекты будут раскрыты подробнее. Итак, в предлагаемой системе тематической индексации Матрица_СМИ дискурс публицистики и региональных неспециализированных СМИ лёг в основу словарей-тезаурусов, составленных для вычисления доминирования разных тематик в сообщениях. Степень доминирования тематики представляет собой числовое выражение, которое складывается из трёх компонентов (см. Рис. 4):
[С. 30] I) Априорный тематический тезаурус широкой предметной области. Именно он позволяет учесть соотношения в тексте нескольких тематик, поскольку он суммирует представленность в анализируемом тексте тезаурусов для всех учитываемых тематических рубрик. II) Априорный тематический тезаурус по узкой тематике. Он устанавливает количество контекстно-независимых и контекстно-зависимых индикаторов по отдельным тематическим рубрикам. III) Апостериорный тематический тезаурус в конкретных текстах. Он определяет количество всех встречающихся в тексте лексических индикаторов. Первые два компонента “делают вклад” в априорную вероятность доминирования темы, 3-й компонент – в апостериорную вероятность. Для первых 2-х компонентов состав и количество лексем-индикаторов заранее задан и предсказуем. В 3-м компоненте мы имеем дело со всем потенциально возможным лексическим составом, то есть с языковым богатством, которое непредсказуемым способом могло формировать смыслы в тексте. Согласно модели, 1-й компонент определяет знаменатель дроби в формуле Байеса, остальные компоненты – числитель дроби. Рассмотрим вышеназванные три компонента подробнее. И 1-й и 2-й компоненты содержат контекстно-независимые индикаторы тематических рубрик. Эти индикаторы представляют собой лексемы или идиомы, которые всегда однозначно (то есть с чрезвычайно высокой вероятностью и ассоциативной устойчивостью) служат индикатором определённой тематики (контекста) в определённой дискурсивной практике. Эксперименты автора на базе системы Матрица_СМИ показали, что контекстно-независимые
индикаторы следует по-разному учитывать для тематик с объёмным («богатым»)
тезаурусом (например, тематики “Спорт” или “Торговля”) и для тематик с небольшим
(«бедным») тезаурусом (например, тематика “Городская дума” или “Областная
администрация”). Следующий элемент расчётов – это контекстно-зависимые лексемы. Они могут служить индикатором тематической рубрики, только при наличие в одном текстовом фрагменте с этими лексемами хотя бы одного контекстно-независимого индикатора данной рубрики. Например слова “судья” или “суд” (в любых склонениях), может служить индикатором тематики “Суды и расследования” или “Преступность”, только при наличии рядом с ними других контекстно-независимых индикаторов, например “прокурор”, “преступн”, “судебн” и т.п. Дело в том, что в переносном значении суды и судьи могут упоминаться в самых разных сферах жизни, а словоформа “суда” и вовсе может означать “морские суда”. Итак, для каждой тематической рубрики (предметной области) заранее создаются, а в процессе индексации текстов корректируются, словари тезаурусы, содержащие контекстно-независимые и контекстно-зависимые лексические индикаторы. Тематическая индексация в системе Матрица_СМИ производится по следующим предметным областям, соответствующим разным сферам жизни: Властные сферы: 1) Федеральные власти, правительство, Госдума РФ; 2) Областная администрация; 3) Областная дума; 4) Муниципалитет и мэрия; 5) Гордума; 6) Коррупция. Экономические сферы: 7) Торговля, сфера обслуживания; 8) Производство, промышленность; 9) Банковский бизнес, акционирование, страхование; 10) Бюджетные финансы, налоги; 11) Нефть, газ уголь, топливо, полезные ископаемые; 12) Атом; 13) Сельское хозяйство и село; 14) Трудоустройство и доходы населения; 15) Экология и природа; 16) Томские компании и предприятия (упоминаемые названия). Культурные сферы: 17) ВУЗы; 18) Наука; 19) Компьютеры и связь; 20)
Школы; 21) Спорт; 22) Культурные мероприятия или организации; 23) Религия. Социальные сферы: 24) ЖКХ; 25) Детство, материнство, семья; 26) Пенсионеры; 27) Транспорт; 28) Здоровье и медицина. Силовые сферы: 29) Преступность, судопроизводство, МВД, ФСБ, МЧС; 30) Армия. Именно такая, а не иная, специализация разных сфер жизни в виде отдельных тематик обусловлена одним из возможных представлений о тематической типологизации сообщений региональных СМИ. В зависимости от потребностей пользователя экспертной системой возможна любая иная разбивка тематических категорий на специализированные подтемы. Например, тематику «Коррупция» также можно отнести в категорию «Силовые сферы и преступность» или в категорию «Экономические сферы». Если какая-то из индексируемых тематик доминирует в конкретном тексте на уровне 100%, это значит, что в данном тексте никаких других тематик из тех, что учитываются, не присутствует. В остальных случаях несколько тематик присутствуют в текстах с разными уровнями доминирования, сумма которых равна 100%. Согласно предлагаемой модели, процент доминирования тематик выражает для пользователя пертинентность результата запроса при поиске текстов с интересующими тематиками (см. Рис. 4). При разработке математического аппарата тематической индексации встал важный вопрос: учитывать ли все случаи встречаемости в тексте однокоренных слов и выражений относящихся к какой-либо тематике, или же учитывать только сам факт наличия в индексируемом тексте лексического инварианта? Иными словами, достаточно ли учитывать лексический индикатор однократно без вариантов его грамматических изменений в тексте? Сплошной частотный анализ не соответствует человеческому восприятию текста и
не всегда позволяет отделить по смыслу главную тему от косвенной второстепенной.
Тематика тем глубже и шире раскрыта, чем больше по ней инвариантных слов и
выражений из тезауруса по данной тематике. Причём, некоторые слова и выражения
будут относиться к определённой тематике, только при наличии в окружающем тексте
других, контекстно-независимых лексических индикаторов темы. Именно инвариантные
слова и выражения из кратковременной памяти человека по ходу восприятия
сообщения затем переходят в долговременные ассоциации и знания, которые
порождаются прочитанным или услышанным сообщением. Согласно предлагаемому здесь подходу достаточно учитывать частотность только единичного вхождения лексического инварианта, а не частоту всех случаев упоминаний лексемы в тексте. В подтверждение рассмотрим пример из сообщения о ремонте концертного зала: 10 раз упоминается словосочетание "концертный зал" (тема культуры) и по одному разу упоминаются 10 разных терминов, напрямую связанных с техническими аспектами ремонта (тема ЖКХ). Никаких других терминов по теме «культура», в сообщении нет. Очевидно, что тема ЖКХ в этом сообщении представлена более многогранно и полно. Она доминирует, над темой культуры, которая представлена лишь косвенно. Таким образом, абсолютная частота встречаемости одного и того же слова вовсе не связана напрямую со степенью доминирования темы. Человеческий интеллект не нуждается в учёте и подсчёте всех случаев употребления в тексте какого-либо термина, чтобы понять текст. Почему в таких подсчётах обязательно должен нуждаться искусственный интеллект, если они не только замедляют его работу, но и делают интерпретацию текста менее корректной? Искусственный интеллект12 может выполнять разного рода стандартизированные задачи многократно быстрее и дольше человека. Практический смысл в использовании искусственного интеллекта появляется только тогда, когда он справляется с решением поставленных перед ним содержательных задач не хуже человека. Поэтому очень важно найти пути приближения компьютерных способов интерпретации текста к человеческим. Эмпирическим экспериментальным путём на базе системы Матрица_СМИ автор
установил, что для пертинентного вычисления степени доминирования определённой
тематики, достаточно учесть, что та или иная лексема или идиома встречается в
тексте в разных склонениях или спряжениях, не перебирая все случаи этих
склонений и спряжений в рассматриваемом текста. Учёт морфологических инвариантов
на уровне пустого морфологического шаблона позволяет, с одной стороны ничего не
пропустить, с другой стороны не делать избыточных подсчётов. Помимо ускорения индексации, вероятностный учёт только инвариантных вхождений полезным последствием данного подхода станет то, что так называемый спамдексинг (злоупотребление частотой ключевых слов, с целью манипулирования поисковыми машинами) потеряет смысл. Нынешние "контент-аналитические войны" между разработчиками поисковых сервисов и разработчиками коммерческих сайтов потеряют свой смысл. В качестве демонстрационного примера вычисления априорной константы индексации для тематик с очень крупным тезаурусом в общих чертах рассмотрим априорный список для тематики "Культурные организации и мероприятия" в региональных СМИ. Всего по данной тематике определено 22 гиперонима (типа культурной деятельности): «Библиотеки», «Просвещение», «Театр», «Архивы», «Понятие сферы культуры», «Путешествия», «Зрители», «Художественность», «Деятели культуры», «Выставки и музеи», «Издательская деятельность», «Скульптура», «Поэзия», «Музыка», «Место проведения культурных мероприятия», «Концерты», «Медиа и кино», «Песня», «Танец», «Праздники местные», «Конкурсы», «Праздники официальные». К каждому гиперониму привязан априорный список лексических инвариантов гипонимических рядов для определения апостериорного количества индикаторов темы в тексте. Далее, согласно принятому стандарту формализации, в поисковом морфологическом шаблоне слов знак «?» означает наличие одного любого символа, а знак подчерка «_» – означает один пробел. Например, если в конце искомой словоформы стоит «??», это означает включение в поисковый тезаурус случая склонения или спряжения слова, выраженных окончанием из двух букв. Поскольку весь список гипонимов очень обширен (более 150), здесь приведён шаблон только для гиперонима «Место проведения культурных мероприятия»: культурн??_центр, ультурн???_центр, филармон, планетари, Хобби-центр, кинотеатр, кинозал, ТЮЗ, органн?? зал, органн??? зал. В Таблице 3 приведён список контекстно-зависимых (второстепенных) индикаторов
тематики "Культурные организации и мероприятия" с пояснениями того, почему
конкретная лексема или идиома не может считаться первичным контекстно-независимым
индикатором.
Подводя итог и возвращаясь к теме статьи, обозначенной в её названии,
рассмотрим вопрос о том, какие перспективы перед гуманитарными исследованиями
открывает использование автоматизированных систем тематической индексации. Можно
предположить, что в перспективе, реализация идеи тематической индексации
приведёт к специализации интернет-поисковиков. Она также позволит поисковым
программам операционных систем автоматически создавать рубрицированный каталог
всех электронных текстов на персональных компьютерах. Тематический поисковик
сможет индексировать файлы и сайты В интеллектуальных поисковиках будущего можно будет исключать из результатов поиска не просто нежелательные слова (их всех не предусмотришь), но и нежелательные тематики; регулировать ранжирование результатов поиска по степени доминирования тематики в текстах или в их фрагментах. Тривиальный поиск по словам, конечно, тоже останется, но он будет уже иметь вторичный характер. Априорные величины для тематической индексации текстов по формуле Байеса могут сформировать только гуманитарии – специалисты в дискурсивных особенностях тех областей знаний, для которых происходит обработка текстов и документов. Речь идёт в частности о составлении дисциплинарных, субдисциплинарных и междисциплинарных идеографических словарей нового типа. В таких словарях по каждой предметно-тематической рубрике будет содержаться список и объяснение всех контекстно-инвариантных употреблений определённых словоформ, понятий или идиом. Для обозначения подобных «сборников контекстов» (с перечислением, но без анализа) в корпусной лингвистике используется термин «конкорданс». Однако существующие конкордансы носят исключительно языковедческо-справочный характер. Здесь же имеется ввиду создание неких предметных баз знаний. Эвристические возможности фильтрации, сортировки и компоновки информации в
такой базе знаний как раз и откроет новые горизонты гуманитаристики. Они станут
действенным поводом для новых форм рефлексии гуманитариев над методами и целями
своих исследований, над своими языками и текстами, и предоставят широкой
аудитории новые поводы заинтересоваться этими текстами. Будь то классические
философские трактаты, электронные архивы сообщений СМИ за прошлые годы, базы
данных с отчётной отраслевой документацией, протоколы заседаний или любые иные
корпуса текстов. У гуманитариев помимо задачи «выписывать из разных книжек в
одну тетрадку», появятся новые более творческие задачи, связанные с поиском
способов автоматизации конспектирования, реферирования и аннотирования текстов.
Автоматизация настраиваемых субдисциплинарных рубрикаций, ранжирования и
комбинаторики текстов создаёт новые стимулы их прочтения, новые направления
интересов, новые способы интерпретации описанных в текстах событий и явлений.
Соответственно, всё это может открыть и новые перспективы гуманитарных наук XXI
века. [1] Сэлтон Г. Автоматическая обработка, хранение и поиск информации. М., 1973. С. 23–24. [2] Соколов А.В. Метатеория социальной коммуникации. С-Пб., 2001; Он же. Общая теория социальной коммуникации. С-Пб., 2002. [3] Ландэ Д.В. Поиск знаний в Internet. М., 2005; Он же. Основы интеграции информационных потоков. Киев, 2006. [4] Ризома – утвердившееся в современных гуманитарных науках понятие постструктурализма и постмодернизма. Оно разработано в книге французских исследователей Ж.Делеза (Deleuze) и Ф.Гваттари (Guattari) «Ризома» (1974). Непосредственно французский термин rhizome заимствован из ботаники и означает специфическую форму корневища, не обладающую четко выраженным центральным подземным стеблем. Понятие введено в гуманитарные дисциплины в противовес понятию «структура» как четко систематизированному и иерархически упорядочивающему принципу организации. Именно характер ризомы в наибольшей степени соответствует свойствам автоматизированной тематической индексации, способной обеспечить пертинентность ответов на поисковые запросы. [5] Термин «онтология» в данном контексте используется в том смысле, в котором он распространился и употребляется специалистами в области семантических подходов к разработке баз данных. См., например: Овдей О.М., Проскудина Г.Ю. Обзор инструментов инженерии онтологий // Труды Шестой Всероссийской научной конференции "Электронные библиотеки: перспективные методы и технологии, электронные коллекции", М., 2004; Соловьев В.Д., Добров Б.В., Иванов В.В., Лукашевич Н.В. Онтологии и тезаурусы. Учебное пособие. Казань, Москва, 2006. [6] Липинский Ю.В. Средства информационного поиска и навигации в больших массивах неструктурированной информации. // Научно-практическая конференция "Проблемы обработки больших массивов неструктурированных текстовых документов" Фонд эффективной политики. 21–22 мая 2001 г.. Режим доступа свободный: http://www.fep.ru/text/dataarrays04.html [7] Формула Байеса: P(A|B) = P(B|A) / P(A)P(B), где P(A) — априорная вероятность гипотезы A (смысл такой терминологии см. ниже); P(A|B) — вероятность гипотезы A при наступлении события B (апостериорная вероятность); P(B|A) — вероятность наступления события B при истинности гипотезы A; P(B) — вероятность наступления события B. [8] Айвазян С.А., Мхиторян В.С. Теория вероятностей и прикладная статистика. М., 2001. С. 68–69. [9] Мэтьюз Р. 25 великих идей. Научные открытия, изменившие мир / Пер. с англ. - СПб., 2007. С. 138–141. [10] Налимов В.В. Вероятностная модель языка. О соотношении естественных и искусственных языков. М., 1979. С. 74–95. [11] Айвазян С.А., Мхиторян В.С. Теория вероятностей и прикладная статистика. М., 2001. С. 269–272. [12] Наука пока понимает лишь некоторые механизмы человеческого интеллекта, в связи с этим под искусственным интеллектом понимается только логико-вычислительная часть разумной деятельности, реализованная в компьютерных системах. При этом не стоит путать интеллект и сознание. Насколько бы близкой не была имитация человеческого мышления компьютером, это ещё не будет означать, что он обладает душой и сознанием. Однако эта проблематика лежит за пределами данной статьи. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||